As Robots May Dream
For the past few months, we've seen an explosion of research breakthroughs throughout the robotics learning community. From this vantage point in early 2026, entropy is high, and I'd like to shed some light on the main categorizations and bets that companies and research labs are committing to.
We seem to have two main categories: VLAs and World Models. Each has its own nuances and advances, but they are the building blocks for a plethora of ideas — as well as a growing cross-pollination across both domains.
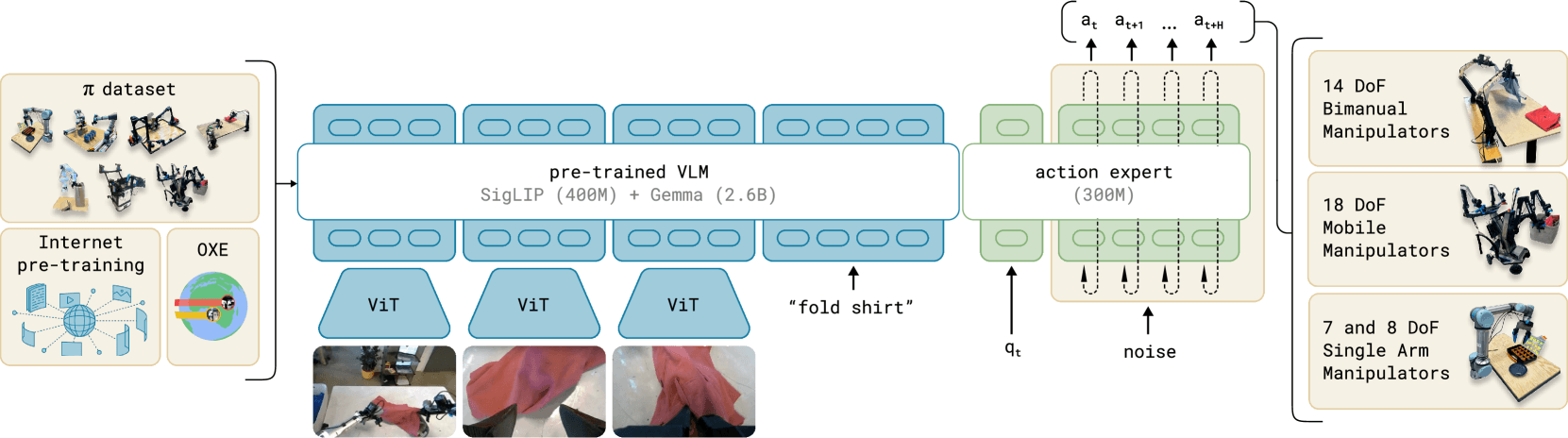
VLAs are observation-action mapping models. They receive observation input (proprioception, language, images, tactile, etc.) and output actions. The most ubiquitous, modern form factor consists of a VLM (vision-language model) backbone and an action expert (a continuous flow-matching policy). You can think of it as System 2 meeting System 1: the VLM (System 2) deliberately learns a dense representation of observation knowledge and maps it to a fast-twitch action expert (System 1) that outputs smooth action chunks.
World models generate and imagine future observations for actions to act upon. This usually involves taking a current observation and action and outputting a future observation: . The architecture is essentially "modeling the future changes in billions of hours of video pixels" like a learned physics simulator.
Our biological structure, at an abstract level, contains a VLA-like architecture — from the cortex handling reasoning and planning to the motor neurons and subcortical regions computing the right actions. At the same time, the brain runs its own world model: the cerebellum maintains internal forward models that predict the sensory consequences of motor commands, continuously simulating what should happen next and correcting when reality diverges from expectation. A copy of motor commands generated by the motor cortex (the efference copy) is sent to the cerebellum, which uses its internal model to predict sensory outcomes — and the mismatch between prediction and reality drives learning. We have both systems, and they work in concert.
But to really understand the differences, we have to dive into the frontier bets that make both these architectures stand. Both sides are taking different routes toward one terminal goal: Embodied General Intelligence.
The VLA Bet
On one side, we have companies like Physical Intelligence, Dyna, and Generalist building generalized, deployable robotic foundation models using the canonical VLA architecture. These companies have entrusted large web-scale VLMs with semantic generalization — the ability to reason and plan over which trajectories to choose. Turns out, if we co-train language with images across different embodiments and environments, we get some juicy generalization gains. The Open X-Embodiment collaboration showed that cross-embodiment models trained on data from 22 different robots across 21 institutions consistently outperformed lab-specific policies, often by 50%. The king of LBMs has confirmed it themselves: vision-language and cross-embodiment data significantly enhance generalization and language-following abilities. The internet is the most immediate, valuable oil deposit for LLM scaling laws — but is it scalable for robotics?
But because these early VLA architectures used transformers end-to-end, they predicted actions as discrete tokens — the same way LLMs predict the next word. RT-2, for instance, tokenized continuous actions into integer bins and decoded them autoregressively. This creates quantized, jerky motions and increases inference time, losing the reactivity and flexibility needed for manipulating the physical world.
In come action experts, tacked on the tail of the VLM. These littler fellas create smoother, multi-modal action chunks that compensate for all the deficiencies that beefy VLMs have.
At this point, it seems like we've nailed the reactivity part. But can we accomplish more complicated tasks? How do we achieve long-horizon trajectories, get the model to keep track of its progress, and possibly recover from failures? How do we thread needles with submillimeter precision?
Currently, not much is being done on the industry side to solve fine-grained manipulation (mostly academic labs are doing the heavy lifting), because the bulk of the trajectory space for commonly automated tasks doesn't require that much accuracy (recovery / generalization can compensate). What is useful — and possibly an instrumental goal for achieving generalization — is solving complex, long-horizon tasks. But based on a sort of bitter lesson intuition, it would be nice to unify this intelligence into one model instead of decomposing each task into subtasks.
So that's what Dyna and co set out to do. They started with one simple but complicated task: folding clothes. From an economic perspective, this is automatable and provides tremendous labor value for a wide market. Dyna's key innovation was a proprietary reward model that provides precise feedback on robot interactions, enabling the policy to not just perform tasks accurately but to autonomously detect and recover from errors. Their system, DYNA-1, achieved a 99.4% success rate operating continuously for over 24 hours — while most competing models encounter unrecoverable errors after an hour or two.
As we move up the task ladder, how do we increase the model's capacity to execute over long trajectories? We could scale up the VLM, but that increases inference time. Optimizations to the flow-matching policy are saturating too. We might need to think outside the box — and quite possibly outside the architecture.
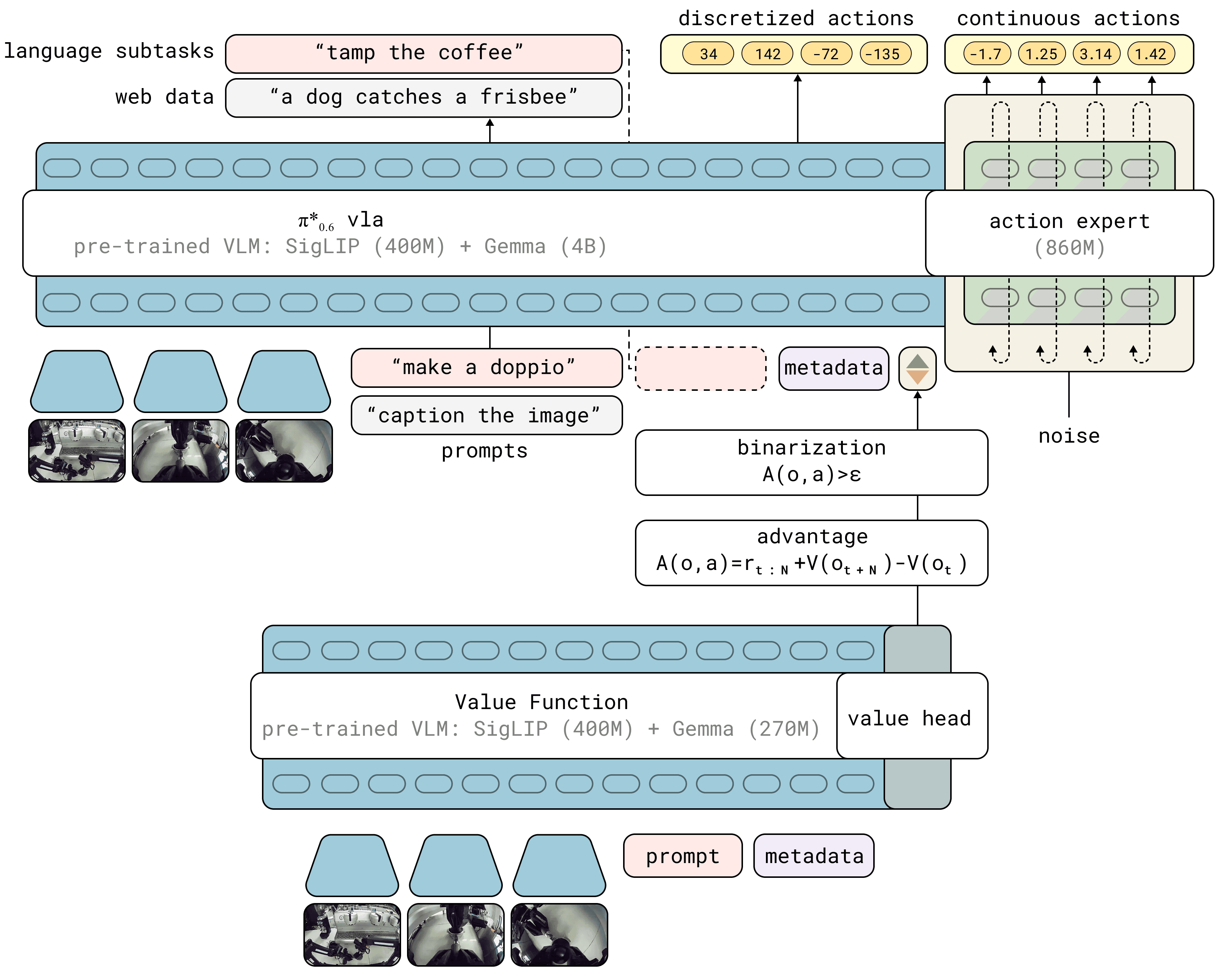
Companies like Physical Intelligence use value functions, which act like scaffolds that signal which trajectories to take. These are typically post-trained after the base policy. The workflow from their π*₀.₆ paper (RECAP) involves a few key steps:
-
Train a value function using offline RL with a static, teleoperated dataset of demonstrations for a specific task (e.g., folding clothes). The value function is initialized from a pre-trained VLM (SigLIP + Gemma 270M) with a value head, and outputs a distributional estimate over discretized value bins.
-
Define a step-cost reward: at each timestep the agent pays a cost of . At the terminal state, it receives for success or for failure:
This makes the value function predict roughly the negative number of steps until success — an elegant, automatic proxy for task progress.
- Compute the advantage using N-step temporal difference ():
This tells us whether the action taken at time led to more progress than expected.
- Binarize the advantage: the advantage is thresholded into a binary improvement indicator:
A clean signal — did this action help or not?
- Condition the action expert: the policy is trained with an additional advantage-conditioned term:
The first term maintains the base policy; the second steers it toward actions the value function deems advantageous.

So every time we have some gangly, complicated task, we collect a few human demos, train this value function, and now it acts like an oracle for the policy to reach "advantageous" positions. Makes it way more efficient too — π*₀.₆ roughly doubled task throughput and halved failure rates on difficult tasks like laundry folding, box assembly, and espresso preparation.
Physical Intelligence unlocked a key formula for navigating difficult tasks: use some external entity like the value function to guide the policy. But we kind of lose that glorified, generalized monolithic model. We have to train a new value function for each new task. Perhaps there are ways to stitch value functions together, but it still strays from the idealized version of a foundation model. Is this the end of the GPT-3-like era as we enter the post-training / finetuning stage?
The World Model Bet
Others were like: "nah we can do better". World models, or more recently, world action models. The timeline of world models overlapped heavily with computer vision and video generation, because it was a natural evolution from models that generate videos to models that generate entire playable worlds.
Although I'm vaguely familiar with the origins, the progression went something like this. Yann LeCun's lab at Meta developed I-JEPA (2023), which learned visual representations by predicting masked image regions in a latent embedding space rather than pixel space — a foundational idea for efficient world modeling. This evolved into V-JEPA (2024), extending the same principle to video and learning spatiotemporal dynamics from masked video prediction. Meanwhile, OpenAI's Sora (2024) demonstrated that large-scale video diffusion models could start to approximate physics. UniPi went further, reimagining robotic decision-making entirely as a text-to-video problem. Video prediction models and world models are architecturally very similar; both learn spatiotemporal dynamics from visual observations. Companies realized that the same transformer and diffusion architectures crushing video generation can be physical simulators.
Most humanoid companies are leading the charge on this front: 1X, Tesla, and NVIDIA. I wondered why world models are such a pressing solution for humanoids specifically. Is it because of the sheer degree of complexity (Elon has said the hand is the hardest biomechanical and robotics learning challenge)? Is it the cost of collecting actionable data via teleoperation compared to action-less egocentric video? But isn't that the same for any embodiment? Why pour enormous resources into an architecture that hasn't yet proved itself?
Three reasons.
First, it's a more compelling, grander vision. The alternative approaches haven't proven themselves at humanoid scale either. The field is placing parallel bets, and world models have the strongest theoretical argument for why they should work.
Second, it's a land-grab. Whoever builds the best world model for physical interaction has a platform-level asset. It becomes the "foundation model" for all downstream embodied tasks, similar to how GPT became a platform. The economics of being second here are terrible, so companies are racing even with incomplete evidence.
Third, embodiment choice bottlenecks the operator's bandwidth. Teleoping a 2-DOF gripper on a fixed arm is manageable. Teleoping a 30+ DOF humanoid with dexterous hands doing whole-body coordination is a nightmare. The 1X World Model shows how seamless this can look — training on 900 hours of egocentric human video, then fine-tuning on just 70 hours of robot data to bridge the embodiment gap.
Now that the timeline makes sense, where are we? Big research labs like NVIDIA are releasing a slew of papers directing toward newer architectures that combine action and observation prediction: World Action Models. Instead of encoding static image-to-action mappings, we encode spatiotemporal physics. DreamZero is a leading example.

DreamZero has a few innovations that make this a reality. First, it trains a joint objective from a pretrained video diffusion backbone for predicting both actions and future observations, aligning action with dynamics:
The left term predicts future video frames; the right term infers the actions that would produce them. By jointly optimizing both, the model learns actions that are grounded in physical dynamics rather than memorized from demonstrations.
A persistent problem with world models is error drift: imagined rollouts accumulate small prediction errors that compound over longer horizons, eventually diverging from reality. DreamZero addresses this with a closed-loop correction mechanism. After predicting one future observation, the system obtains the real observation from the environment and fits it into the KV cache before predicting the next one. This grounds the model's imagination in reality at each step, preventing hallucinated futures from drifting too far.
The result: over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs, with real-time 7Hz closed-loop control through a 38x inference speedup of the 14B parameter model.
The fundamental limitation I see is the size of the model and the quadratic memory complexity in the context window. A 14B-parameter video diffusion model is not cheap to run, and each step of the autoregressive rollout appends observations to the KV cache, growing memory and compute quadratically with horizon length. Current optimizations like speculative decoding and KV cache compression help, but at some point you're fighting the transformer's attention mechanism itself. Whether the field solves this with more efficient architectures (state-space models, linear attention) or simply waits for hardware to catch up remains to be seen.
Where This Is All Going
Where does this leave us? The VLAs and World Models seem to want to solve the same thing. Physical Intelligence's value functions are a form of learned internal evaluation: predicting future returns is, in a fundamental sense, predicting something about the future. That starts to look like a lightweight world model. NVIDIA's world action models are world models that directly output actions, which starts to look like a VLA with imagination.
Yet both share the same handicap: they are still trained by imitation learning. Therefore they are bounded by the dataset distribution. What are we missing?
If we look at large language models' advances in language and formal reasoning, it is achieved through outcome-based reinforcement learning within dense, verifiable environments like AlphaZero. This requires a massive leap of faith: trusting emergent predictive signals instead of imitation learning.
But the nature of the task is completely different. In math, the logical structure of a proof is the credit assignment. Each step depends on the previous one in a way that's traceable. But in robotics, there's thousands of possible ways to grab a spoon. Intermediate traces are incredibly dense and low information.
As Sergey Levine, co-founder of PI, has noted, goal specification is the greatest advantage in robotics. We can constrain the problem so hard (to an object-centric or sub-task space) that we don't need dense credit assignment.
Is goal specification sufficient to replace the role that verifiable reasoning traces play in enabling self-play RL? Or do we also need something like a world model so the agent can do mental rollouts and self-evaluate?
I really don't know the answer to this, but I can envision how these two can work together. Because the world model seems to want to play a more grandiose role of predicting action, observation, and value, it can act as some global transition function that can move between different value function spaces. Then within each value function space we can retrieve specialized external gadgets that zero-in on the task (like Pi's trained offline RL value function, test-time steering tools like VLS, or residual RL policies for fine-grained manipulation).
A totally left-field alternative universe could be that sim gets incredibly cheap due to AGI coding agents. They can write rule-specific reward functions and iterate within hyperrealistic physics simulators (which they also build). They can domain-randomize parameters and robustly deploy to the real world (given mild human supervision, or not!), reducing dynamics gaps and modeling better sensors.
The road seems uncertain.